timing and structure in live comedy
I wanted to understand how comedians balance prepared material with improvisation.
In 2017-2018, I recorded the audio of 25 live stand-up comedy shows from two different tours across two countries.
Under the supervision of Prof. Elaine Chew and Dr Rebecca Stewart, I developed a new computational methodology for mapping performance dynamics. The resulting paper, Timing Structures in Live Comedy: A matched-sequence approach to mapping performance dynamics, is published by PNAS Nexus.
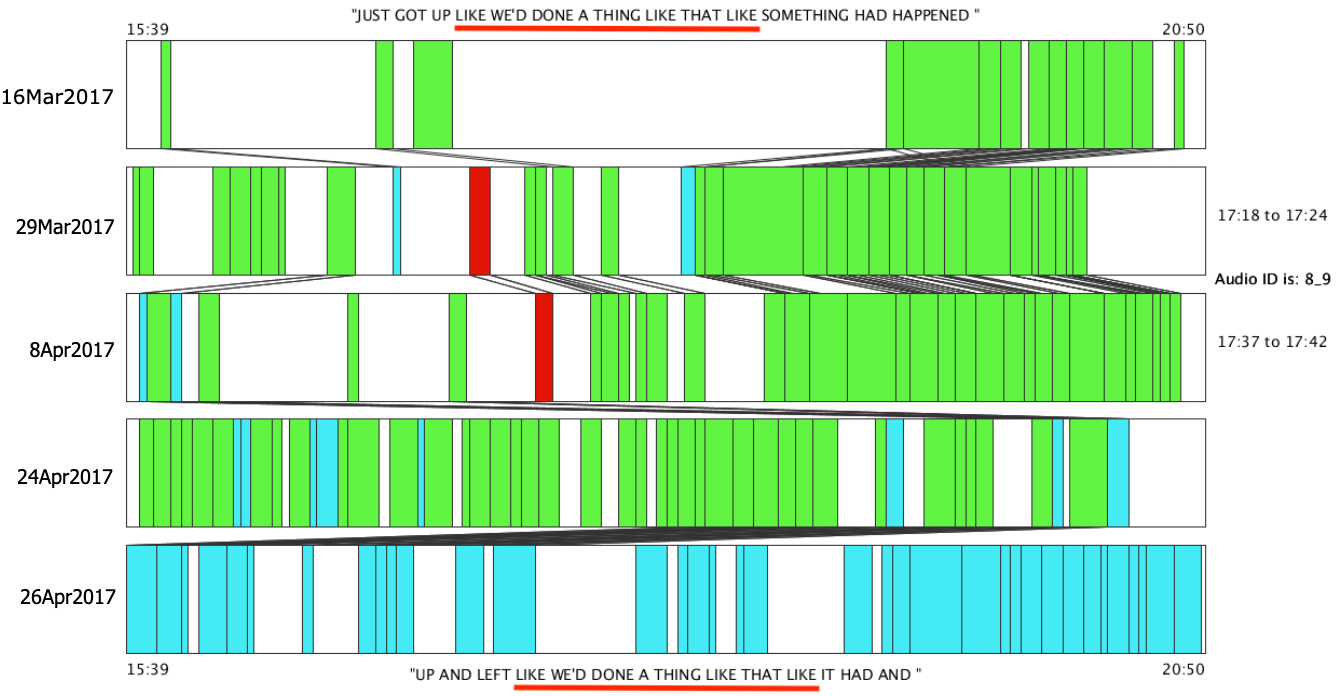
I compared different performances of the same show to one another, looking for precise matches between show transcripts.
I chose words and word-like sounds (“um”) as the basic unit of comparison, also called a “token,” and looked for exactly matching sequences of six tokens or more. I then mapped their location in performance time to see how systematic the re-use of material and timing was.
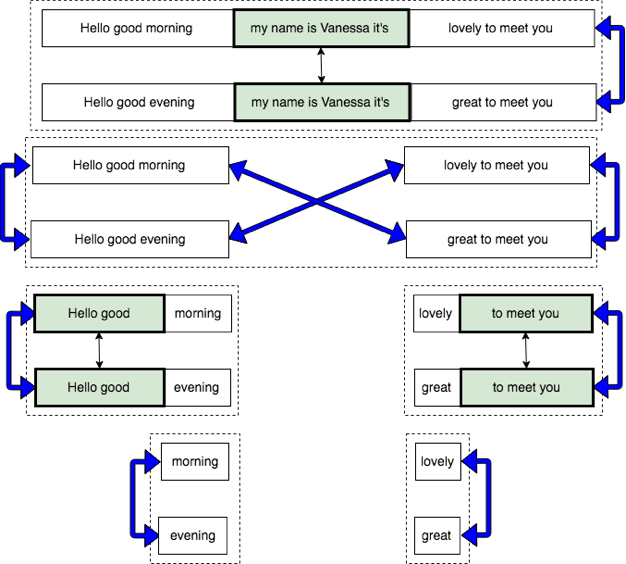
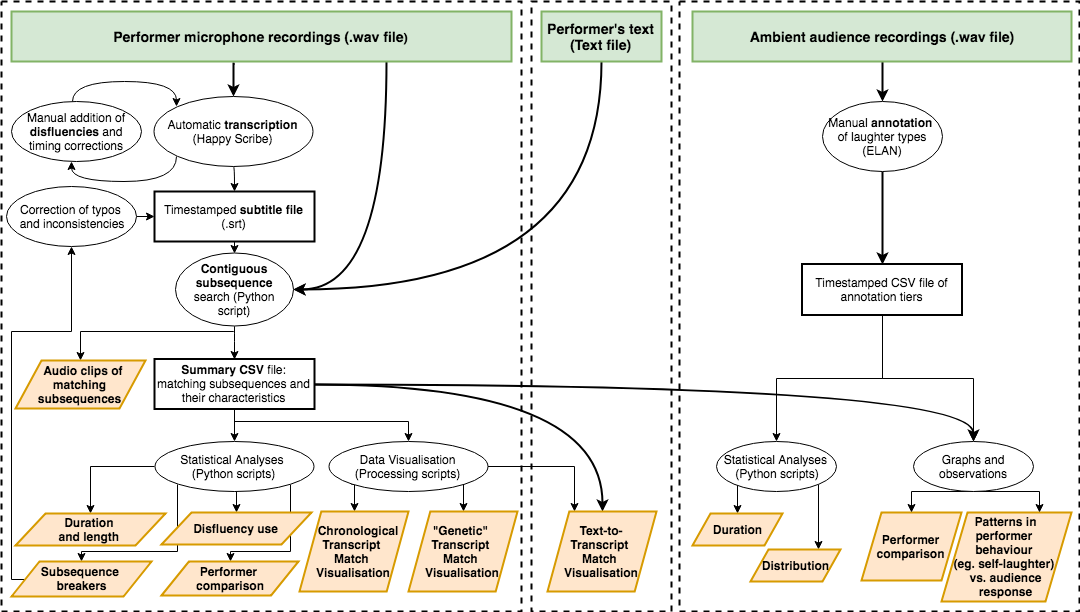
Diagram showing the flow of data analysis
By mapping the placement of material that matches between stand-up comedy shows, you generate a picture of the structure of its spontaneity. The matching sequence maps provide a visual reference for the amount of structure in both the material and timing of a show.
These visual representations are similar to the internal reference I have in my practice as a theatre director and dramaturg: some sections need to be loose and responsive, some need to be tight and precise in order for the show to connect with its audience.
The algorithm and analysis techniques that make up Topology Analysis of Matching Sequences (TAMS) borrow ideas from studies of genetic variation. For example, we assume that a match that persists across all shows is critical to the show’s function, much as a gene that all humans is more likely to be vitally important than one present in only 50% of the population.
By comparing shows, I discovered that the two comedians had different approaches to timing in their shows, and that both occasionally included hesitation sounds like “um” and “ah" in sequences that matches across many shows.
TAMS can be applied to any time-stamped transcripts and I look forward to exploring different types of performed speech, but also to explore how non-verbal art forms such as dance adapt to audiences by treating movement and spatial configurations as sequences.